The myth of Linux tweaking

If you have been a Linux user for some time now, then you must have come across more than one article telling you how to improve the speed and responsiveness and whatnot of your Linux distribution at home. In fact, the Web is awash with guides and tips on tuning your system to the max, offering the promise of greatness to those bold enough to redirect values into /proc.
The reason why we are here, today, we few, we happy few, we band of geeks, is to discuss this delicate topic, or rather, to debunk it. Because Linux desktop tweaking is nothing short of a big, juicy placebo, right there alongside Windows tweaking, which gives you more or less the same outcome, only with more GUI.
Reality check
Let’s start with the overview of what Linux is. It’s a product of thousands of people. Specifically, the kernel is developed by highly skilled programmers, employed by serious companies, with tons of contributions from many more thousands of volunteers and enthusiasts across the world. The Linux kernel is used in all the top supercomputers, it powers the backbone of the Internet, it’s used for media rendering, and everything else besides. It’s a pretty robust beast, well designed to meet the rigorous demands of the world’s colorful digital markets.
Yet, for some reason, now and then, people online disagree. It ain’t tuned enough.
Does this sound plausible to you? Do you really think that occasional users know better than the collective mind of a whole army of professionals, coding veterans, kernel gurus, filesystem and network experts, and the assorted lot of knights and paladins? Do you really think that Linux is just not good enough by design that its defaults need to be altered?
With this in mind, let us take a look at some of the typical examples for where would-be tuning is supposed to render miracles with your boxes, give them that extra juice you don’t normally get. In other words, all the cases where the collective intelligence of the Linux development world fails the arbitrary forum thread post test.
I/O scheduler
Oh my, if you change noop to deadline, you will get a whatever percentage boost. Not. I have seen this written in at least nine thousand tutorials, almost copypasta, with little regard to the actual problem at hand. The thing is, applying any tunable without knowing what the target software is supposed to do is pointless. More so if you have a generic system, which serves a generic purpose, with different programs, running almost at random times, each with their own unique work profile.
But let’s put that aside. Why would changing the scheduler help? Do you mean to say the folks who ship Linux the way it is have never actually seen and tested their software, and simply decided to go with an arbitrary option? What kind of I/O are you going to be doing? What is so special about your desktop that it merits tweaking? In the worst case, you will be working with a lot of small files on the disk, in which case, you want a faster disk. In the best case, you will be working with large files, in which case, you want a faster disk. In both scenarios, you won’t go beyond the physical capabilities of the device called hard disk.
Most people do not use their hard disks that much to notice any significant improvement. In fact, let’s illustrate. Assume you need to copy ten 4GB files and one thousand 40KB files every single day, from one hard disk to another. This could be your typical backup, which presumably runs at night. I/O scheduler tweaking will probably yield minimal results when working with large files, so your total copy time will be roughly 40GB/disk speed, or approx. 100MB/sec. In other words, you will copy your big data in about 400 seconds, or seven minutes.
With the small files, I/O tweaking could help shorten the time needed to process requests. This is where we might want to take a look at the iostat command, and its output. Interesting fields are the following r/s, w/s, await, svctm. The first two tell us how many requests are being processed each second for the selected device. The third (await) one tells us the average time, in milliseconds, it took for a request to be processed. Finally, svctm (service time) is the time it takes for the relevant block device to complete the request.
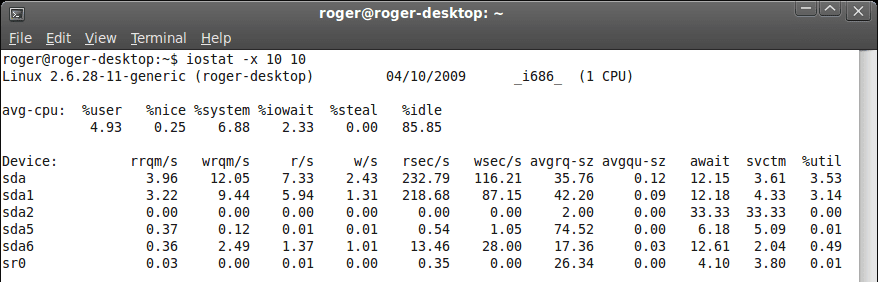
There are no golden numbers, but if you look around, you will see that a typical system can process something like 500-600 requests per second. Moreover, the wait time will be at most 15-30 ms, while the service time will often not exceed 20 ms under normal load conditions. If we look at our task, which is to copy 1,000 files, even without any optimization whatsoever, the system could process all the requests in about one and a half second. And we would not notice anything, because the human threshold for interactive latency is about 400 ms. Indeed, copying 40MB of data is well below the maximum throughput of even average hard disks. And to make things worse, the copying is actually done into the disk cache first.
Yes, you may have wondered about that. But most hard disk also come with a cache, often 32-64MB in size, which is used as the target for the write requests. Data is placed there first, and then asynchronously written to the actual permanent storage. This should not concern you, whatsoever, because the disk controller is in charge of this whole scheme, and you should let it be.
But we’re talking about optimization. Let’s assume a magical 50% improvement. This means you would save virtually nothing for large files, and about half a second for the small ones. And if you could double the speed somehow, the grand improvement would still be about three and a half minutes every day.
And now, some real results. My daily home backup runs over a 1Gbps line from one standard mechanical hard disk to another. A grand total of 262,000 files (and growing) are being processed every time, with 35,500 files/min, an average of 6,700 new files are copied every day, at an average rate of 900 files/min. The total data is worth 133GB, with some 650MB copied at an average rate of about 1.5MB/sec. The backup job takes approximately seven minutes.
In this case, the disk capabilities and the I/O scheduling are less critical than the CPU power needed to read all the file attributes and compare them to the destination, in order to decide whether to perform a copy, or leave the target as it. Even your best tuning will not make even the slightest difference. On average, the disks are hardly loaded at some 2% of its total capacity.
SSD TRIM
Here’s another hot potato. It sounds fancy, but it actually means the following: Allow the operating system to inform the SSD disk controller that certain blocks of data are no longer in use, so they can be wiped. Why would we want something like this? Well, to improve write speed, supposedly. When the SSD is empty, then writing data is just one operation. When there’s old, unused junk there, then it needs to be deleted first, and then the new stuff written, so basically, two operations.
Sounds good. And therefore, the Internet is full of articles telling people to activate this function for their devices in Linux distributions that do not support the functionality out of the box, or in those cases where TRIM is available and has not been turned on by default.

All your TRIM are belong to us, source: wikimedia.org, licensed under CC BY-SA 3.0.
First, as to the actual benefit of doing something like this, please see the previous section. As to whether you should do this, think about it. Someone, probably more knowledgeable than you has thought it prudent not to include TRIM in the system defaults, possibly because of the risk of data consistency and corruption. Not because they wanted to give you a sub-par experience. Not because they wanted their product to suck, so you can be disappointed. Most likely because the drawbacks outweigh the benefits. And now, you’re about to play with your hard disk, which contains valuable information, and you’re about to use an unsupported command. Good luck. Speed! Sure, you’ll get your three and a half minutes daily. After you spend a few hours trying to recover data from a slaughtered filesystem.
Swappiness & vm tunables
What a cool word, is it not. I have actually written about this in my third hacking article, with another long, numerical exercise on the actual benefits of making these kind of changes. Sure, tuning the swappiness values can help with old laptops, which have a shortage of physical memory and slow hard disks, but this only proves my point. Get better hardware, and Bob’s your uncle. The same applies to all memory-related tunables.

Network tuning
Upgrade your network card, your ISP, your router, something. There is no problem with your Linux. And if it’s not doing torrents just as well as you expected, the problem is most likely NOT with the internal functionality of the network stack in your kernel. Why do you think that your distro can’t handle the few MB of movies or whatnot that you’re trying to download? Do you honestly believe that all Linux developers are just 54Kbps users and that they do not care about fast Internet?
Here’s an article from a lad who knows his stuff. Most people will look at this and say, I wanna. Wait. Did you read the little paragraph that says high-performance computing? Your laptop is not a high-performance computing machine. It says, multi-user desktop, good, systems serving thousands of concurrent network clients, bad. That’s exactly the point. Linux distributions are configured for the widest range of use cases, and they offer the most balanced and optimal experience overall. You will never need anything else.

Source: wikimedia.org, (c) Justin Smith, CC BY-SA 2.5.
Speaking of that earlier resource, results and an actual usage profile would be cool, because otherwise, we don’t have any good visibility into how these tunables affect the server, and what the affected server might actually be. Which brings me to a personal example.
My personal experience
Now, let’s brag a little. In all my years working with Linux and tweaking the hell out of it for clear business purposes, and this is what I’m paid to do, among other cool things, I have only encountered a single situation where kernel tuning really made any real difference to the overall performance of the running software. The sad sobering reality is, most of the time, easy and quick gains are achieved by upgrading the hardware, like the CPU or disk, and fixing and optimizing the actual software. Never the kernel.
Well, except in this one case, a 32-core, 64-thread MySQL server with 128GB RAM, processing some 1,500 requests every second, and it wasn’t handling the load. I spent about a week figuring out the actual customer flow. I figured out how long it took for a single request to complete, and the rate the server was gobbling then. Them, I tweaked the TCP parameters to more quickly rinse old connections, and I carefully matched the MySQL settings to the server capabilities, in order not to create a bottleneck during the initial torrent of requests, so that the CPU queue was filled with about 128 processes, twice the number of worker threads. And so, all considered, I merely changed just three tunables under /proc, and more importantly, tweaked the MySQL memory and I/O cache values, in the software’s own configuration file. That was it.
On the other hand, there was this other situation where I spent a couple of weeks fiddling with every conceivable CPU scheduler tunable, playing with critical nanosecond values, only to get a total improvement of absolutely nothing, and simply by optimizing the multi-threading model in the customer software, I got much better and consistent results.
So yes, in the vast majority of cases, upgrade the CPU to one with a higher frequency, dump in an SSD or such, and you will have improved your system tenfold over any, most careful tuning and tweaking that you can possibly think of.
Conclusion
Server tuning is one thing. But wait. All those with a real server, raise your hand. Good. Not you. Now, desktop users, raise your hands. Excellent. You don’t need to do anything. Kernel tuning at home is black magic, voodoo, hocus-pocus, now you see me now you don’t. It’s a pointless and even dangerous exercise that will buy you a few seconds or minutes at most, and cost you all you hold dear, at worst.
This is actually true for all desktop operating systems. Let them be. Don’t poke them. The benefits are not worth the hassle, not worth the possible complications down the road, which you will not even be able to correlate to the few supposedly innocent tweaks you introduced back then. Let your system run as it is, it is already optimized. For a headache-free experience.
Cheers.
All seemed to made sense until you started talking about TRIM. Perhaps you are still not using SSDs extensively on your computers and have little experience with them and never got really interested.
Enabling it is not just a matter placebo tuning. it does affect write speeds in a major way (and sometimes read speeds too, to some extent), in addition of substantially reducing long term SSD wear, which is important especially as newer models have less durable cells than older ones (many of which didn’t even have hardware TRIM support. Since they were so durable it didn’t matter much).
You can still user modern-day SSDs without it as their controller will try still hard dealing with the added burden on wear leveling, but consumer ones, which don’t have large amounts of reserved space for wear leveling purposes (called “overprovisioning”) that enterprise SSDs have in order to provide performance consistency and write endurance, suffer from this. They are intended to be used with TRIM, not without.
For still not being able to write a reliable TRIM implementation and thus not being able to enable it by default when other operating systems do, Linux kernel programmers are to blame, not thank.
What SSD wear? A disk dies after 10 years? Let them reach that age first. Moreover, you only emphasize my point. No reliable implementation, so you go with an unreliable one for your data. Right. Oh, I am using SSD massively.
Cheers,
Dedoimedo
Honestly, sorry, but I disagree. Your whole list is great, and I can agree with everything but TRIM. There is a reason if every major os (Windows, OSX, Android, Most Linux distro) ship with it enabled.
Yes, you won’t see much difference at least in the mid-short period, but why would you want your driver to die faster/run much slower?
Oh, and I agree that the user shouldn’t enable TRIM. It should be enabled by the distribution (unless you run LFS/Arch/Gentoo, then you’re obviously on your own).
He’s not saying SSD Trim is useless, he’s saying is not yet in a good enough state for Linux developers to enable it by default. Do you seriously think Linux developers are unaware of the benefits of Trim? The point is if Linux developers think it is not yet reliable enough you probably shouldn’t turn it on.
P.S. Great Article!
Thanks, cheers!
Dedoimedo
Excellent article all around and I agree about TRIM by the way.
One minor niggle though and that’s the vm.swappiness tweak. The default level for just about any Linux distro is set at a level of 60(% of physical memory used before swapping out to disk cache). This is fine for a true server set up but it’s rather terrible for for desktops/laptops running a 64-bit Linux distro unless you’re running more than 4 GB of memory. And it’s not just for users running old hardware as 4 GB of physical memory is still quite the norm for modern consumer hardware these days.
In my experience I’ve found that for anyone running a 64 bit distro on a modern or fairly modern dual core or quad core machine with 4 GB of memory (DDR2 or DDR3), the default vm.swappiness setting of 60 means that the disk cache can be quickly utilized even under moderate use slowing the (Linux based) OS to a crawl. Setting vm.swappiness to 20 however, eliminates this problem easily without introducing any liabilities.
vm.swappiness @ 60 is a terrible idea for a true server (i.e. anything with 100+ GB of RAM) because swapping out while you still have 50G+ of RAM is just dumb. Needless to say, many of us are running databases or webservers without a physical swap device (and significantly more memory, i.e. DL560 w/ 1.5TB of RAM) so trying to swap out is even more dumb.
If you are talking about the majority of desktop users, they probably only start tweaking after they have encountered an actual performance issue with their over-bloated-shiny-desktop-environment (or whatever it is they are running).
To help that group, introduce them to debugging tools. When my system is running slowly, it is very useful to glance over at Gkrellm (or down at ksysmon, whatever) to check whether disk, memory or CPU is the bottleneck, and see which process is actually impacting my experience.
Additionally, metrics like those are how you can prove to your audience that performance tweaks are having no effect, so it can help to ram your point home. I guess you must use a few tools to measure the impact (or not) of your tweaking.
Hmm, found this on reddit this morning. Sorry but I have to disagree on a lot of your article here. Your closing statements are contradictory considering that you rated the product that I and my team created as being “ultra-fast and highly responsive”. I do hope you realize that we weren’t using many kernel defaults.
Kernel defaults are just that, defaults. They tuned to accommodate all possible situations. They are neither the best nor the worst for every situation. Just as with server tuning, desktop tuning is equally important for speed and response times and these parameters should be adjusted to seek the best possible configuration for the expected use-case. We spent a lot of time tuning for desktop use at Fuduntu and you raved about it. ;) I don’t know that common users need to spend a lot of time doing tuning, it should be done upstream in the distributions in my opinion, but I thought I’d point out that contrary to your article the tuning work we did to some of the very parameters you’ve called out like deadline and swappiness helped lead you to label our distribution the best and “ultra-fast”. That doesn’t mean that every parameter should be adjusted, but there are a number of them that will help boost performance for the desktop use-case.
I think I’m in the same boat as you Andrew.
> Do you really think that occasional
users know better than the collective mind of a whole army of
professionals, coding veterans, kernel gurus, filesystem and network
experts, and the assorted lot of knights and paladins?
Absolutely. One guy can prove an army of “professionals” wrong and improve a software project. Sometimes it’s because he’s not deeply entrenched in their thinking and mindset.
> Linux distributions are configured for the widest range of use cases,
and they offer the most balanced and optimal experience overall. You
will never need anything else.
That is a contradiction. It is either balanced or optimized, not both. And as far as never needing anything else, there’s this quote about 640K of memory I remember…
People who make linux distros are people, not “knights and palidins”, “experts”, “gurus” etc. Why are they being put on some sort of pedestal for worship? Casual users should not be dissuaded from trying to tweak or improve their system. Yes, hardware upgrades provide some of the surest performance improvements, but they can cost lots of money. Tweaking settings is free. Doing this stuff also helps you learn about what makes your computer work. The spirit of Linux is to do it yourself. Remember how this whole shebang got started: some uppity casual computer user decided to tweak his OS to be better than Minix.
Agree! When I went to ask for suggestions on how to tune my Linux server to serve more requests (the max was like 2000 reqs/sec) 5 guys out of 5 said “upgrade your server CPU, ram, hard disk and put Mysql, Riak, Redis..” what the heck really? If I just were so wealthy I’d do that and program from the Bahamas. I ended up by doing it myself with Redis + Lua + Nginx and tweaking system variables like somaxconn, tuned hard disk with Hdparm etc.. and guess what? The server now processes 18k reqs/sec easily with just the same hardware instead of 10 servers with the latest tech costing $200 each with 20 databases and untuned system. Seriously, I will never understand this mentality. Keep it Stupid Simple but tune where you can.
Well, the default mount option for ext4 includes the “atime” option (instead of “noatime”). Linus Torvalds himself said that is the most stupid and resource consuming mount option ever (paraphrasing very roughly). So it’s not all myth about tweaking. I don’t really understand why this option is default, perhaps, since most of the time it’s server-oriented, it has some server-related utility at the same time it’s not a great compromise due to superior hardware to begin with. It still makes one wonder why desktop-oriented distros preserve that, perhaps it’s just “inertia”, the path of least resistance/work.
The truth is, that while a good deal of the “tweaks” are just based on “it feels faster”, there are some cases, not all that rare, of people who actually do benchmarks and such things. At the same time, even the mainline evolves, sometimes towards the direction of what such tweakers were pointing (like switching from noop to CFQ, and possibly futurely to BFQ.
And distros themselves are nothing but just a big package of different tweaks. And in turn they often have some other packages that allow for further tweaking in the defaults, like “cpufreqd”, “and”, and “ulatencyd”.
Enabling discard on SSDs is an important *reliability* tweak. It was disabled by default because the Linux kernel implementation used to be very slow (it was never a good *performance* tweak even though hypothetically it should have been). As implementations improve, it is becoming enabled by default in newer kernels. http://www.howtogeek.com/176978/ubuntu-doesnt-trim-ssds-by-default-why-not-and-how-to-enable-it-yourself/